
8.8 表记录的查询操作
数据库的所有操作中,表记录查询是使用频率最高的操作。在 MySQL 中,使用 select 语句实现表记录的查询。select 语句的功能是让数据库服务器根据客户端的请求查找用户所需要的信息,并按用户规定的格式整理成“结果集”返回给客户端。
select语句语法格式:
select字段列表
from数据源
[where过滤条件]
[group by分组表达式]
[having分组过滤条件]
[order by排序表达式 [asc|desc] ];
说明:from用于指定数据源,数据源可以是一个或多个表。
8.8.1 指定字段列表及列别名
字段列表用于指定查询结果集中所需要显示的列,可以使用以下格式指定字段列表。
* :字段列表为数据源的全部字段。
表名.* :多表查询时,指定某个表的全部字段。
字段列表 :指定所需要显示的列。
字段列表可以指定字段名也可以指定表达式,还可为字段名指定别名,多个列之间用逗号隔开,字段的顺序可以根据需要任意指定。
说明:多表查询时同名字段必须加表名作为字段名的前缀。
例如查询MySQL服务器的当前时间,所用的SQL语句如下。
select now();
例如查询student表中全部数据(全部记录和全部字段),所用的SQL语句如下。
select * from student;
例如查询student表中学生姓名及学号信息,所用的SQL语句如下。
select student_name,student_no from student;
8.8.2 使用谓词限制记录的行数
MySQL中的两个谓词distinct和limit可以限制记录的行数。
(1)使用谓词distinct过滤重复记录。
select 语句用于查询数据库表中指定字段的所有数据,但是有时会出现重复信息。如果只希望查询那些具有不同记录值的记录信息,可以使用谓词关键字distinct。
语法格式:
select distinct列名
例如查询student表中学生姓名信息(要求姓名不能重复),所用的SQL语句如下。
select distinct student_name from student;
(2)使用谓词limit查询某几行记录。
使用select语句时,经常要返回前几条或者中间某几行记录,可以使用谓词关键字limit。语法格式:
select字段列表
from数据源
limit [start,]length;
说明如下。
(1)limit接受一个或两个整数参数。start表示从第几行记录开始输出,length表示输出的记录行数。
(2)表中第一行记录的start值为0(不是 1)。
例如查询score表的前3条记录信息,所用的SQL语句如下。
select * from score limit 0,3;
该语句等效于“select * from score limit 3;”。
例如查询score表中从第2条记录开始的3条记录信息,所用的SQL语句如下。
select * from score limit 1,3;
8.8.3 使用from子句指定多个数据源
在实际应用中,一个select查询语句往往需要从多个数据库表中提取数据,通过在from子句中使用各种连接(join)运算,就可以将不同数据源表中的记录组合起来。MySQL中的连接可以分为内连接(inner join)和外连接(outer join),外连接又分为外左连接(left join)和外右连接(right join),分别简称为左连接和右连接。
1.内连接(inner join)
内连接将两个表中满足指定连接条件的记录连接成新的记录集,舍弃所有不满足连接条件的记录。内连接是最常用的连接类型,可以通过在from子句中使用inner join实现,语法格式如下。
from 表1 [innert] join 表2 on <表1和表2间条件表达式>
2.外连接(outer join)
外连接只限制一个表,对另一个表不加限制(该表的所有记录出现在结果集中)。外连接又分为左连接(left join)和右连接(right join)。
(1)左连接。左连接表A和表B意味着取表A的全部记录按指定的连接条件与表B中满足连接条件的记录进行连接,若表B中没有满足连接条件的记录,则表A中相应字段填入NULL。左连接可以通过在from子句中使用left join实现,语法格式如下。
from表1 left join表2 on <表1和表2间条件表达式>
(2)右连接。右连接表A和表B意味着取表B的全部记录按指定的连接条件与表A中满足连接条件的记录进行连接,若表A中没有满足连接条件的记录,则表B中相应字段填入NULL。右连接可以通过在from子句中使用right join实现,语法格式如下。
from 表1 right join 表2 on <表1和表2间条件表达式>
右连接表 A 和表 B 的结果与左连接表 B 和表 A 的结果是一样的,也就是说“select A.name,B.name from A left join B on A.id=B.id”和“select A.name,B.name from B right join A onB.id=A.id”执行后的结果集是一样的。
 如果在from子句中指定了多个表,而这些表中又有同名的字段,使用这些字段时应该在字段名前冠以表名,以表明该字段属于哪个表。
如果在from子句中指定了多个表,而这些表中又有同名的字段,使用这些字段时应该在字段名前冠以表名,以表明该字段属于哪个表。
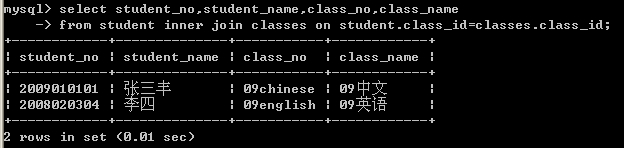
内连接和外连接的区别在于内连接将去除所有不符合条件的记录,而外连接则保留其中部分。左连接与右连接的区别在于如果用表A左连接表B,则表A中所有记录都会保留在结果集中,而表B中只有符合连接条件的记录在结果集中;右连接则相反。例如从student表和classes表查询学生的班级信息,所用的SQL语句如下(下面的SQL语句也可以省略inner关键字),该SQL语句的运行结果如图8-29所示。
select student_no,student_name,class_no,class_name
from student inner join classes on student.class_id=classes.class_id;
从3个表中查询数据,相应的select语句可以写成下面的语法格式:
from表1 [innert] join表2 on <表1和表2间条件表达式> [innert] join表3 on <表2和表3间条件表达式>
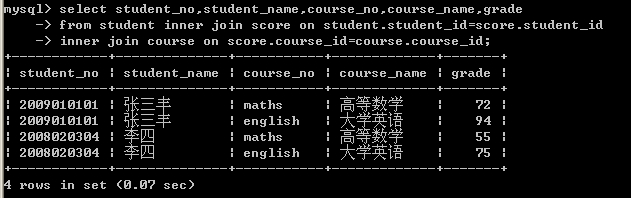
例如从student表、score表和course表查询学生的成绩信息,所用的SQL语句如下。
select student_no,student_name,course_no,course_name,grade
from student inner join score on student.student_id=score.student_id
inner join course on score.course_id=course.course_id;
该SQL语句的运行结果如图8-30所示。
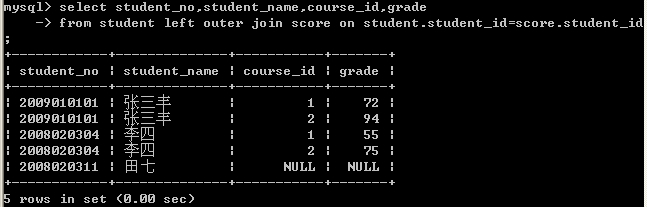
例如,从student表和score表中查询数据,查看student表中有哪些学生,以及这些学生的学生成绩如何,所用的SQL语句如下(outer关键字可以省略)。
select student_no,student_name,course_id,grade
from student left outer join score on student.student_id=score.student_id;
当学生田七没有选修任何课程时,运行结果如图8-31所示。
8.8.4 使用where子句过滤记录
由于数据库中存储着海量的数据,用户往往需要的是满足特定条件的部分记录,这就需要对记录进行过滤筛选。在select语句中使用where子句可以设置记录的过滤条件。
where子句的语法格式:where <过滤条件>
这里的过滤条件是一个逻辑表达式,满足表达式的记录包含在查询所返回的结果集中。
例如,在score表中查询成绩大于80的记录,所用的SQL语句如下。
select * from score where grade>80;
例如,查询“10中文”班级所有的学生信息,所用的SQL语句如下。
select student_no,student_name,class_no,class_name
from student join classes on student.class_id=classes.class_id
where class_name= '10中文';
例如,查询课号“maths”成绩大于60的学生记录,所用的SQL语句如下。
select student_no,student_name,course_no,course_name
from student join score on student.student_id= score.student_id
join course on score.course_id=course.course_id
where course_no= 'maths ' and grade>60;
例如,查询课号“maths”成绩大于等于60且小于等于90的学生记录,所用的 SQL语句如下。
select student_no,student_name,course_no,course_name
from student join score on student.student_id= score.student_id
join course on score.course_id=course.course_id
where course_no= 'maths ' and grade between 60 and 90;
说明:between…and…是一个逻辑运算符,用于测试一个值是否位于指定的范围内。
例如,查询“10中文”班级和“10英语”班级的学生信息,所用的SQL语句如下。
select student_no,student_name,class_no,class_name
from student join classes on student.class_id=classes.class_id
where class_name= '10中文' or class_name= '10英语';
也可以写成如下代码。
select student_no,student_name,class_no,class_name
from student join classes on student.class_id=classes.class_id
where class_name in( '10中文' , '10英语');
说明:in是一个逻辑运算符,用于测试给定的值是否在一个集合中。
例如,在student表中查询class_id值为空的记录,所用的SQL语句如下。
select * from student where class_id is NULL;
说明:is是一个逻辑运算符,这里不能写成“select * from student where class_id=NULL;,”NULL是一个不确定的数,不能使用“=”和NULL比较。
例如,在student表中查询“张”姓的学生记录,所用的SQL语句如下。
select * from student where student_name like '张%';
说明:like和not like是个逻辑运算符,用于模式匹配。SQL模式匹配允许使用“_”匹配任何单个字符,使用“%”匹配任意数目字符(包括零个字符)。
例如,在student表中查询带有“三”字的学生记录,所用的SQL语句如下。
select * from student where student_name like '%三%';
例如,在student表中查询第二个字为“三”的学生记录,所用的SQL语句如下。
select * from student where student_name like '_三%';
 上面的select语句中,如果where子句中含有中文符号,需要设置character_set_client、character_set_connection、character_set_database、character_set_results为gbk字符集。
上面的select语句中,如果where子句中含有中文符号,需要设置character_set_client、character_set_connection、character_set_database、character_set_results为gbk字符集。
8.8.5 使用order by子句对记录排序
select语句返回的结果集由数据库系统动态确定,往往是无序的,order by子句用于设置结果集的排序。在select 语句中添加一个order by 子句,就可以使结果集中的记录按照一个或多个字段的值进行排序,排序的方向可以是升序(asc)或降序(desc)。
order by子句的语法格式:order by{<排序表达式1>[asc|desc]}[,…[<排序表达式n>[asc|desc]]
说明如下。
(1)<排序表达式>用于指定排序的依据,既可以是字段名,也可以是字段名在字段列表中的位置。在order by子句中可以指定多个字段作为排序的依据,此时首先按照前面的字段值进行排序,然后在该字段值相同的记录中按照后面的字段值进行排序。
(2)排序的过程中,MySQL将NULL处理为最小值。
例如,从score表中按照成绩从高到低的顺序提取数据,所用的SQL语句如下。
select * from score order by grade desc;
例如,从score表中按照成绩从低到高的顺序提取数据,所用的SQL语句如下。
select * from score order by grade asc;
也可以写成“select * from score order by grade;”,默认为升序。
例如,从score表中按照成绩从低到高,成绩相同的按照student_id从高到低的顺序提取数据,所用的SQL语句如下。
select * from score order by grade,student_id desc;
8.8.6 使用聚合函数返回汇总值
聚合函数用于对一组值进行计算并返回一个汇总值,常用的聚合函数有 sum、avg、count、max和min 等。除count函数外,聚合函数在计算过程中忽略NULL值。聚合函数经常与group by子句一起使用,其功能可参考“PHP数组”章节中“数组统计函数”的内容,这里不再赘述。
(1)使用sum函数计算字段的累加和。例如统计score表中course_id等于1的总成绩,所用的SQL语句如下。
select sum(grade) from score where course_id=1;
(2)使用avg函数计算字段的平均值。例如统计score表中course_id等于1的平均成绩,所用的SQL语句如下。
select avg(grade) from score where course_id=1;
(3)使用count函数统计记录的行数。例如统计student表中的学生人数,所用的SQL语句如下。
select count(student_id) from student;
也可以写成“select count(*) from student;”。
(4)使用max函数计算字段的最大值。例如统计course表中course_id等于1的最高分,所用的SQL语句如下。
select max(grade) from score where course_id=1;
(5)使用min函数计算字段的最小值。例如统计course表中course_id等于1的最低分,所用的SQL语句如下。
select min(grade) from score where course_id=1;
8.8.7 使用group by子句对记录分组统计
group by子句将指定字段值相同的记录作为一个分组,该子句通常与聚合函数一起使用。
group by子句语法格式:group by 字段
例如,在score表中查询每个学生的平均成绩,所用的SQL语句如下。
select student_no,student_name,avg(grade)
from score inner join student on score.student_id=student.student_id
group by score.student_id;
8.8.8 使用having子句提取符合条件的分组
having子句用于指定组或聚合的查询条件,该子句通常与group by子句一起使用。having子句与where子句都用于指定查询条件,不同的是where子句查询条件在分组操作前应用,而having查询条件在分组操作之后应用。having子句语法格式与where子句语法格式类似,但having子句中可以包含聚合函数。
having子句语法格式:having <查询条件>
例如,在score表中查询学生平均成绩高于70分的学生记录,所用的SQL语句如下。
select student_no,student_name
from score inner join student on score.student_id=student.student_id
group by score.student_id
having avg(grade)>70;
 在线客服
在线客服
共有条评论 网友评论